Blog
Before You Pick an AI Model, Know What You're Paying For!
Deploying AI agents is no longer the hard part — knowing what they cost and whether they're worth it is. This article breaks down how to measure orchestration cost per patient, match model tiers to specific ROI goals, and use A/B testing to make model selection a data-driven decision rather than a guess.
By Joon Lee
In almost every engagement I walk into, the answer is some variation of "we don't really know." Teams have an invoice. They have a vendor. They have a story about productivity. What they don't have is a number that ties what the agent consumed to what the agent produced — at the level of a single patient, a single panel, a single run.
That gap is the entire ROI conversation. The real question isn't whether AI agents deliver value. They can. The question is whether you can measure what they cost and what they produce well enough to make the next decision.
Measure the Cost of Every Run
When you deploy an agent that processes a 100-patient panel — pulling demographics, diagnoses, medications, labs, vitals, encounter histories, HEDIS gaps, and risk scores — you are not making a single API call. You are orchestrating hundreds of tool calls and a long tail of reasoning steps that compound differently depending on which model is doing the thinking.
So before arguing about which model is "best," you need to know what each one consumed. Same agent. Same configuration. Same panel. Three model tiers — Lite, Regular, and Heavy.
| Metric | Lite | Regular | Heavy |
|---|---|---|---|
| OU per patient | 0.53 | 0.79 | 0.91 |
| Total OU (100-patient panel) | 53 | 79 | 91 |
| OU premium vs. Lite | — | +49% | +72% |
Care management margins are thin. If the agent costs more to run than the incremental enrollment revenue it surfaces, you don't have an ROI story — you have a technology problem dressed up as an operations investment. Every run on KORA produces a full cost trace: OU consumption, token usage, tool call counts, and run duration. You always know exactly what you spent.
Match the Model to the Goal, Not the Hype
Cost on its own tells you nothing. Higher OU consumption does not automatically mean better output. The cheapest model is not automatically the best value. The benchmark made that clear.
| Metric | Lite | Regular | Heavy |
|---|---|---|---|
| Eligible patients identified | 35 (36%) | 83 (86%) | 70 (70%) |
| HEDIS gaps found | 5 | 35 | 37 |
| Combined ROI identified | $109K | $198K | $158K |
Regular costs 49% more OU than Lite and identifies 81% more revenue opportunity. It catches 28 more HEDIS gaps and surfaces behavioral health candidates that Lite missed entirely. By any reasonable definition of return on investment, Regular dominates Lite.
Heavy is the most expensive option and generates the least revenue. What it produces is more conservative output: a stricter clinical evidence threshold, more borderline patients in a "reassess" bucket. That is not a worse model. It's a different posture.
"There is no universally 'best' model. There is only the best model for your ROI goal."
Three goals. Three answers.
A/B Test Your Models — Don't Guess
Here's the part most AI vendors won't tell you. The model powering your agent was picked during development based on general benchmarks and gut feel. Then it shipped. Then nobody looked back.
That works fine — until it doesn't. Models evolve. Pricing changes. New tiers appear. The model that was optimal six months ago may be outperformed by a cheaper one today. You will never know if you don't measure.
This isn't a one-off marketing exercise. It's a methodology deployed on every agent:
- Hold the agent constant. Identical system prompt, tool list, and workflow logic. The model is the only variable.
- Hold the data constant. Same patient panel from the same EHR snapshot. Differences in output are attributable to model behavior, not data variance.
- Compare on metrics that matter. OU consumption, eligible patients identified, HEDIS gaps surfaced, projected revenue — all normalized for direct comparison.
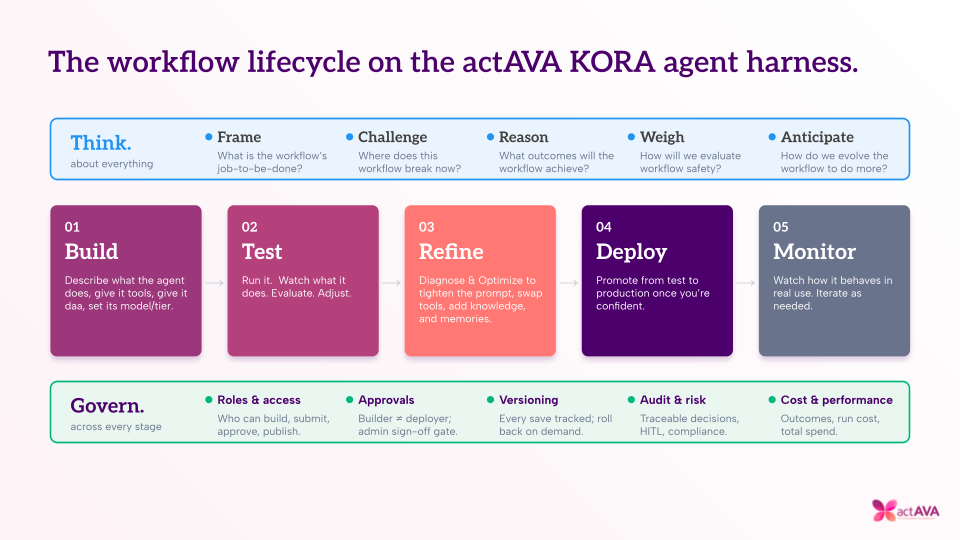
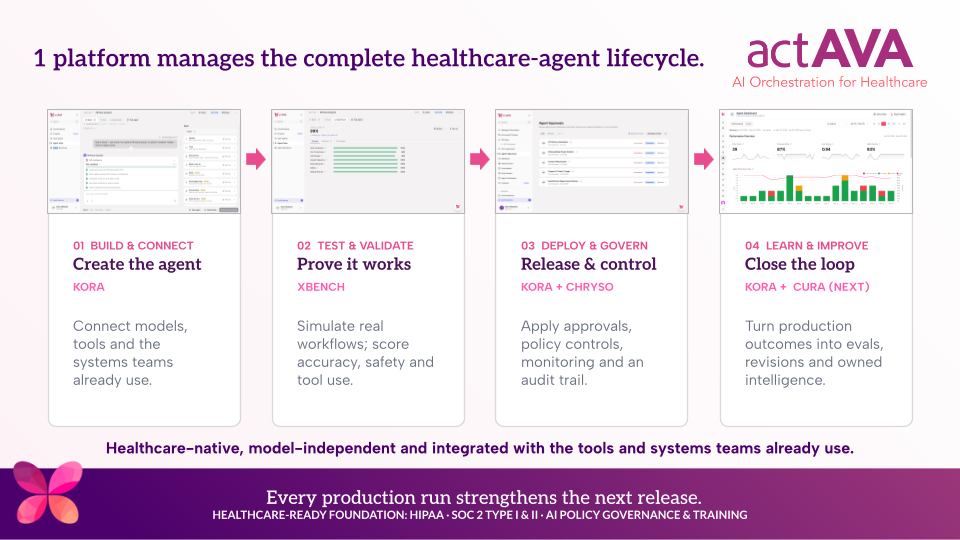
This is plain old A/B testing — standard practice in software engineering and almost nonexistent in healthcare AI deployment. The KORA platform closes that gap through three purpose-built layers:
This isn't a feature bolted on for a sales deck. It's the architecture.
The Bottom Line
Most AI platforms give you a single model, a single price, and a "trust us, it works" deployment. They can tell you the agent ran. They can't tell you what it cost per patient, whether a different model would have surfaced more revenue, or how output quality compares across tiers.
In the engagements I run, the conversation that turns a pilot into a production commitment is almost never the demo or the dashboard. It's the number that ties cost to value, run by run — and the methodology to keep that number honest as the model landscape shifts underneath you.
You have a measurement problem.
Solve that first, and model selection stops being a leap of faith
and becomes a number you can defend.
See the Benchmark in Action
Explore the Enrollment Workflow Agent benchmark — or learn how KORA applies this methodology to prior auth, clinical documentation, care gap outreach, and population health analytics.

Written by
Joon Lee
Lead Forward Deploy Engineer